
嵌入式深度学习一: TensorRT初探
本文由在当地较为英俊的男子金天大神原创,版权所有,欢迎转载,本文首发地址 https://jinfagang.github.io 。但请保留这段版权信息,多谢合作,有任何疑问欢迎通过微信联系我交流:
jintianiloveu
嵌入式的必要性
我们知道,在很多时候我们的深度学习模型需要部署到嵌入式中,而不是仅仅在PC机里面运行。首先考虑的因素是成本,嵌入式的板子无论如何成本都远比PC机要低,其实是考虑工控条件,其实嵌入式的板子很容易在恶劣的环境下保持稳定的工作效率。这里的嵌入式,包括FPGA,Tegra TX2,这样的嵌入式设备。
在复杂工况下能够稳定工作,那么它离产品就更近了一步。我想在不远的将来,嵌入式深度学习设备会像现在手机一样普遍,但是它却不是手机的形态,因为它为用户提供着看不见的人工智能服务,最终表现的形式长久以来依旧会是手机UI界面或者VR的效果。
TensorRT
TensorRT是英伟达推出的一个运行环境,它可以将tensorflow训练好的模型,通过TensorRT的运行环境进行解析,使之可以推理在GPU上,这种技术可以大大的加快深度学习模型推理的速度,而这个东西就能同时做到降低成本和加速的作用。我觉得未来人工智能硬件产品至少会出现以下两种形态:
- 以树梅派为代表的低端产品,比如一个运行着简单图片分类网络或者人脸识别网络的监控器;
- 以Tegra TX2等为代表的高端产品,比如一个集成了自动驾驶功能的电动车(电动汽车或者电动车),一个集成了自动跟踪和检测功能的无人机;
我们在一个深度学习模型推出之后,往往是遵循这么一些步骤来部署:
- 用一个框架比如Caffe,TensorFlow或者其他框架train好模型;
- 使用cuda加速或者cudnn等来加速部署,但是这种也仅仅是用框架自带的cuda实现;
- 但是最终推理的时候还是在CPU上进行inference。
而我们实际上在部署深度学习模型需要具有这么一些特点:
- 高吞吐量:一次性可以处理多个请求;
- 低反映延迟时间:这需要模型具有快速的给出结果的能力,这样才能在较低的延迟上给出结果;
- 低功耗:在PC上不需要考虑低功耗的问题,但是到了部署阶段,低功耗将是一个主要考虑的问题,因为功耗过高会导致设备大量发热,最终到达设备可以工作的极限状态,最终整个设备将变得不可用。
- 部署独立性:部署在实际系统上运行的软件需要尽可能的减少以来,并且需要精简到最小化。
TensorRT部署加速步骤
其实在TensorRT上部署优化也非常简单,两张示意图就可以了解所有:
第一步:
从训练好的模型,比如TensorFlow的frozen model,导入到TensorRT能识别的模型当中,最终会生成基于TensorRT的可部署策略:
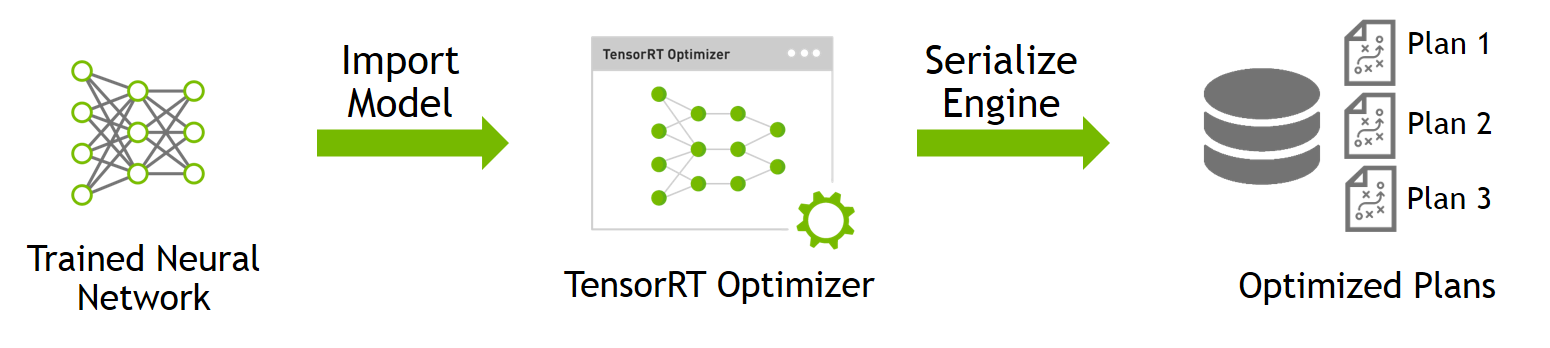
这个步骤做了两个工作,首先将其他框架训练好的模型,导入到TensorRT中,然后TensorRT会对这个模型进行优化,具体优化策略是充分利用GPU的并行计算能力,把相同架构的卷积层合并成一个个的块。示意图如下:
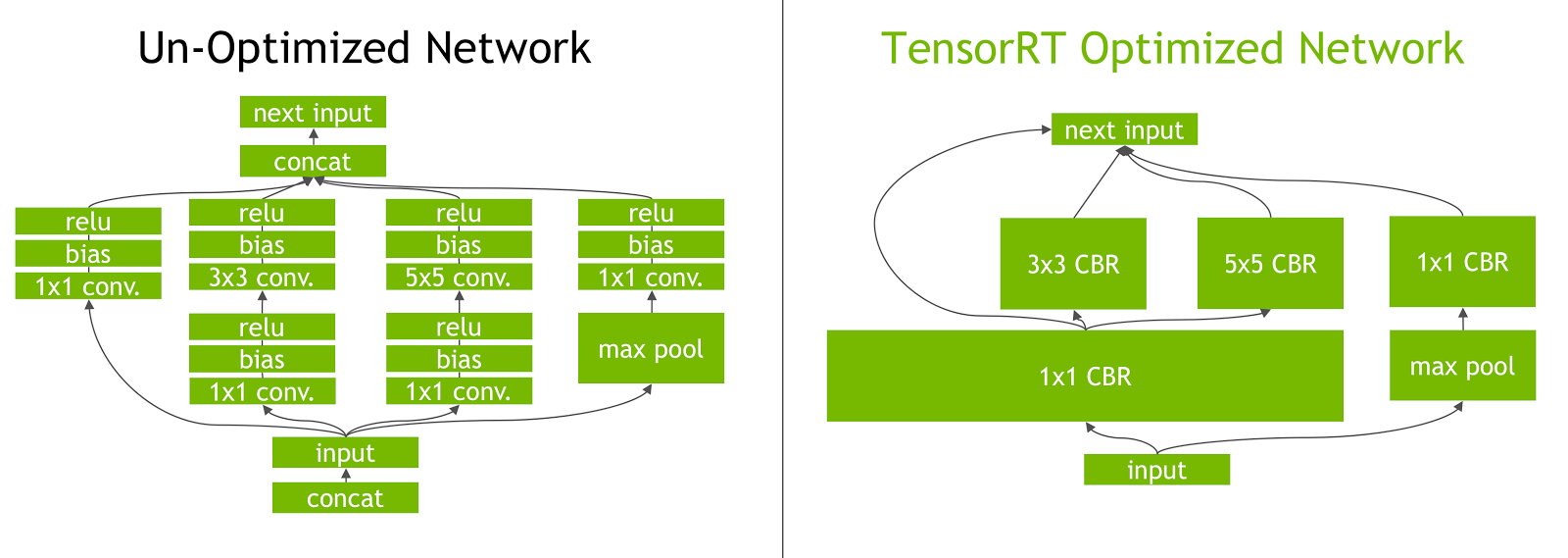
简单的来说,这一步工作只需要做一下内容:
|
|
或者从caffe来优化一个模型:
|
|
这个就把TensorFlow训练好的模型,导入为了UFF,Universal Framework Format,并且告诉UFF, 你的输出层的名字是什么。
第二步:
将框架训练好的模型反序列化为TensorRT的 plan以后,就可以用这个plan将它部署在TensorRT的引擎上了,这里尤其是嵌入式的tx2设备:

TensorRT官方层的局限,以及自定义层
在TensorRT官方的实现中,支持的层只有常见的一些layer,基本上够用,包括:
- Convolution
- LSTM and GRU
- Activation: ReLU, tanh, sigmoid
- Pooling: max and average
- Scaling
- Element wise operations
- LRN
- Fully-connected
- SoftMax
- Deconvolution
但是如果是一些定制化程度比较高的层,比如:MultiBoundingBox, NMS,这样的层是没有的,这个时候就需要自己去实现了,而在TensorRT中,定义了一个写扩展层的接口,在C++里面继承它,并实现相应的方法就可以让这个层运行在TensorRT上:
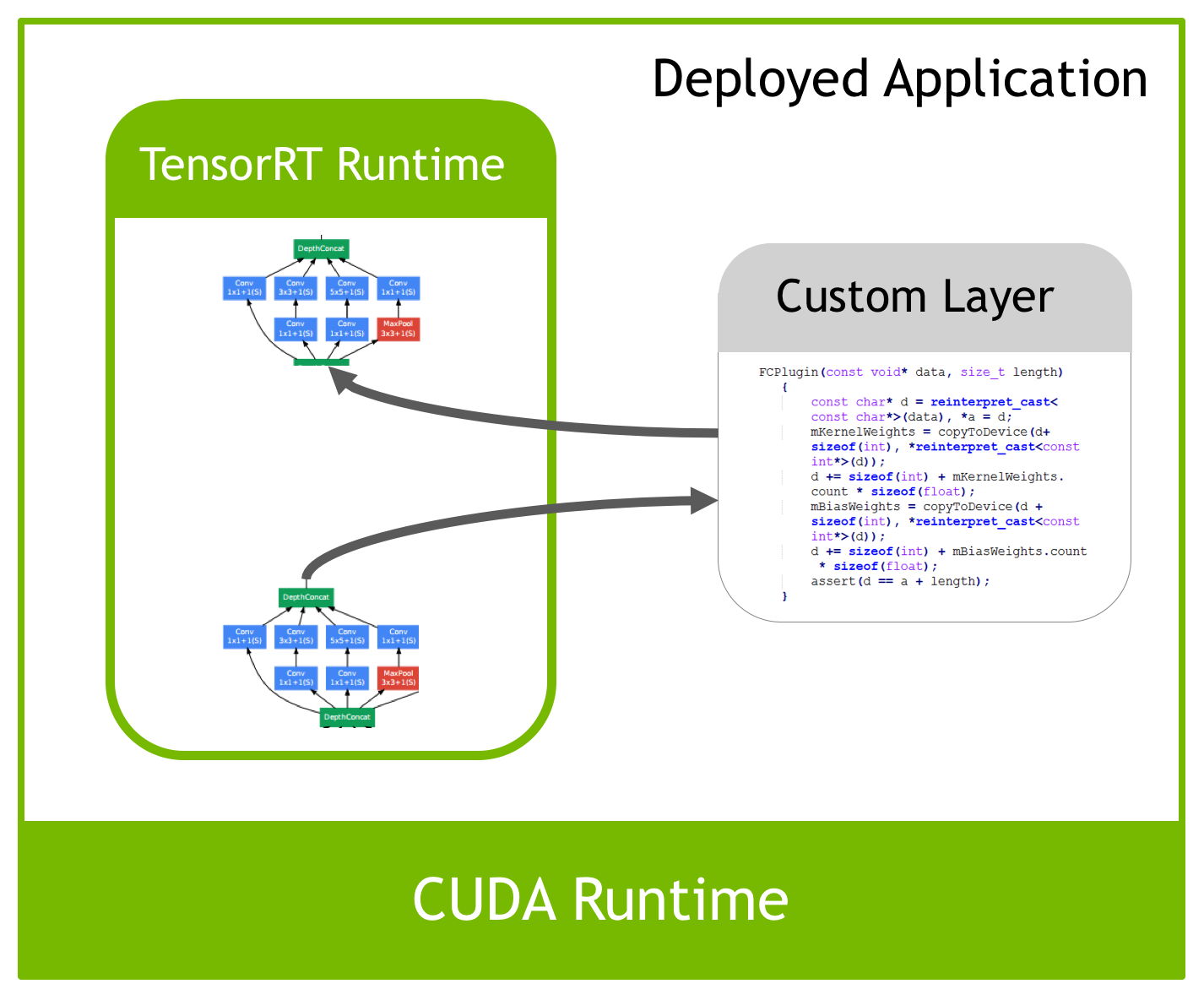
TensorRT Sample Codes
从Sample Codes来看一下如何加速这些东西。
