本文介绍 paddlepaddle系列之三行代码从入门到精通
paddlepaddle系列之三行代码从入门到精通
本文由在当地较为英俊的男子金天大神原创,版权所有,欢迎转载,本文首发地址 https://jinfagang.github.io 。但请保留这段版权信息,多谢合作,有任何疑问欢迎通过微信联系我交流:jintianiloveu
序
这将是paddlepaddle系列教程的开篇,小生不才,得以给百度paddle运营大使撰写这份paddlepaddle入门教程,当然是非官方的。既然是非官方,自然会从一个使用者的角度出发,来教大家怎么用,会有哪些坑,以及如何上手并用到实际项目中去。
我之前写过一些关于tensorflow的教程,在我的简书上可以找到,非常简单基础的一个教程,但是备受好评,因为国内实在是很难找到一个系列的关于这些深度学习框架的教程。因此在这里,我来给paddlepaddle也写一个类似的教程,不复杂,三行代码入门。
三行代码paddlepaddle从入门到精通
paddlepaddle是百度大力推出的一个框架,不得不说相比于tensorflow,paddlepaddle会简单很多,接下来我会细说。同时百度在人工智能方面的功底还是非常深厚,我曾经在腾讯实习,类似于AT这样的公司,甚至没有一个非常成型的框架存在。
既然是三行代码精通paddlepaddle,那么得安装一下paddlepaddle。就目前来说,最好的办法是build from source。步骤如下 (注意,这里是CPU版本,GPU版本的源码编译过程后续补充,我们先用CPU来熟悉API):
1 2 3 4 5 6 7 8 9 10 11 12 13
| # clone 最新代码到paddle git clone https://github.com/PaddlePaddle/Paddle paddle cd paddle mkdir build cd build make all -j8 sudo make install # 安装python接口,注意paddlepaddle目前貌似只支持python2,因此在写脚本的时候一定要兼容一下python3 # 这里是mac的情况下,如果是ubuntu /usr/local/opt 应该直接是/opt/ sudo python -m pip install /usr/local/opt/paddle/share/wheels/*.whl # 或者直接 sudo pip2 install /usr/local/opt/paddle/share/wheels/*.whl
|
好了,看上去应该算是安装完了。接下来我们用三行代码来测试一下?
paddlepaddle在python API上0.10有较大的变化,所以直接import一下v2版本的API。如果可以说明paddlepaddle安装没有问题。这里赞一下百度的技术功底和用户体验,这尼玛要是caffe或者caffe2编译出错概率100%不说,python安装了也不能import,paddlepaddle一步到位,非常牛逼。
闲话不多说,直接三行代码来熟悉一下paddlepaddle的API。
三行代码来了
接下来要做的事情是,用paddlepaddle搭建一个3层MLP网络,跑一个二维的numpy随机数据,来了解一下paddlepaddle从数据喂入到训练的整个pipeline吧。
首先我们这个教程先给大家展示一个图片分类器,用到的数据集是Stanford Dogs 数据集, 下载链接, 大概800M, 同时下载一下annotations, 大概21M。下载好了我们用一个paddle_test的文件夹来做这个教程吧。
1 2 3
| mkdir paddle_test cd paddle_test mkdir data
|
把所有的images 和 annotations扔到data里面去,解压一下:
1 2 3 4
| paddle_test └── data ├── annotation.tar └── images.tar
|
顺便说一下,这里的annotations是为后面用paddlepaddle做分割做准备,本次分类任务,只需要一个images.tar就可以了,所有图片被放在了该类别的文件夹下面,以后处理其他分类任务时,只需要把不同类别放在文件夹就OK了,甚至不用改代码,非常方便,这比MXNet要有道理很多,多数情况下我们根本不需要海量图片训练,也没有必要搞个什么imrecord的数据格式,MXNet导入图片真心蛋疼,没有Pytorch方便,但是Pytorch得运行速度堪忧。
OK,将images.tar解压,会得到120个文件夹,也就是120个类别,每个类别里面都是一种狗狗图片。比如这张是一只 Beagle:

我们现在要来处理一下这些蠢狗。
开始写三行代码
好了,开始写三行代码了.
1 2 3 4 5
| def vgg_bn_drop(input_data): def event_handler(event): def train():
|
实际上paddle的使用也就是三行代码的事情,首先是网络构建,这里我们构建一个VGG网络,其次是event的处理函数,这个机制是paddle独有的,paddle把所有的训练过程都包装成了一个trainer,然后调用这个event_handler来处理比如打印loss信息这样的事情。OK,我们一步一步来,先来看一下train的过程把:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| def train(): data_dim = 3 * 32 * 32 class_dim = 10 image = paddle.layer.data( name="image", type=paddle.data_type.dense_vector(data_dim)) net = vgg_bn_drop(image) out = paddle.layer.fc(input=net, size=class_dim, act=paddle.activation.Softmax()) lbl = paddle.layer.data( name="label", type=paddle.data_type.integer_value(class_dim)) cost = paddle.layer.classification_cost(input=out, label=lbl) parameters = paddle.parameters.create(cost) print(parameters.keys()) momentum_optimizer = paddle.optimizer.Momentum( momentum=0.9, regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128), learning_rate=0.1 / 128.0, learning_rate_decay_a=0.1, learning_rate_decay_b=50000 * 100, learning_rate_schedule='discexp') trainer = paddle.trainer.SGD(cost=cost, parameters=parameters, update_equation=momentum_optimizer) reader = paddle.batch( paddle.reader.shuffle( paddle.dataset.cifar.train10(), buf_size=50000), batch_size=128) feeding = {'image': 0, 'label': 1} trainer.train( reader=reader, num_passes=200, event_handler=event_handler, feeding=feeding)
|
paddle的网络训练流程分为几个步骤:
- 首先定义网络,这里的网络不包括最后一层的softmax;
- 创建一个cost,cost当然就需要一个网络的输出和lable了;
- 通过这个cost来创建网络训练的参数,非常简单明了;
- 最后是优化器,这里定义反向传播的正则项,学习速率调整策略等;
- 通过上面这些创建一个trainer;
- 最后这个trainer要训练起来,还需要持续的数据喂入,时间处理函数,和喂入的方式。
接着我们看一下网络定义和事件处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
| # define VGG network def vgg_bn_drop(input_data): def convolution_block(ipt, num_filter, groups, dropouts, num_channels=None): return paddle.networks.img_conv_group( input=ipt, num_channels=num_channels, pool_size=2, pool_stride=2, conv_num_filter=[num_filter] * groups, conv_filter_size=3, conv_act=paddle.activation.Relu(), conv_with_batchnorm=True, conv_batchnorm_drop_rate=dropouts, pool_type=paddle.pooling.Max()) convolution_1 = convolution_block(input_data, 64, 2, [0.3, 0], 3) convolution_2 = convolution_block(convolution_1, 128, 2, [0.4, 0]) convolution_3 = convolution_block(convolution_2, 256, 3, [0.4, 0.4, 0]) convolution_4 = convolution_block(convolution_3, 512, 3, [0.4, 0.4, 0]) convolution_5 = convolution_block(convolution_4, 512, 3, [0.4, 0.4, 0]) drop = paddle.layer.dropout(input=convolution_5, dropout_rate=0.5) fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear()) bn = paddle.layer.batch_norm( input=fc1, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear()) return fc2 def event_handler(event): if isinstance(event, paddle.event.EndIteration): if event.batch_id % 100 == 0: print("\nPass %d, Batch %d, Cost %f, %s" % ( event.pass_id, event.batch_id, event.cost, event.metrics)) else: sys.stdout.write('.') sys.stdout.flush()
|
这里我们先用paddle内置的cifar10来测试一下能否训练起来,把上面的代码加上import之后:
1 2 3 4 5 6 7 8
| from __future__ import print_function, division import paddle.v2 as paddle import sys paddle.init(use_gpu=False, trainer_count=1) if __name__ == '__main__': train()
|
在主函数里面运行train()。见证奇迹的时刻到了。。
paddle开始下载数据,并打印出了网络结构!

so far so good,paddle开始训练网络!!!
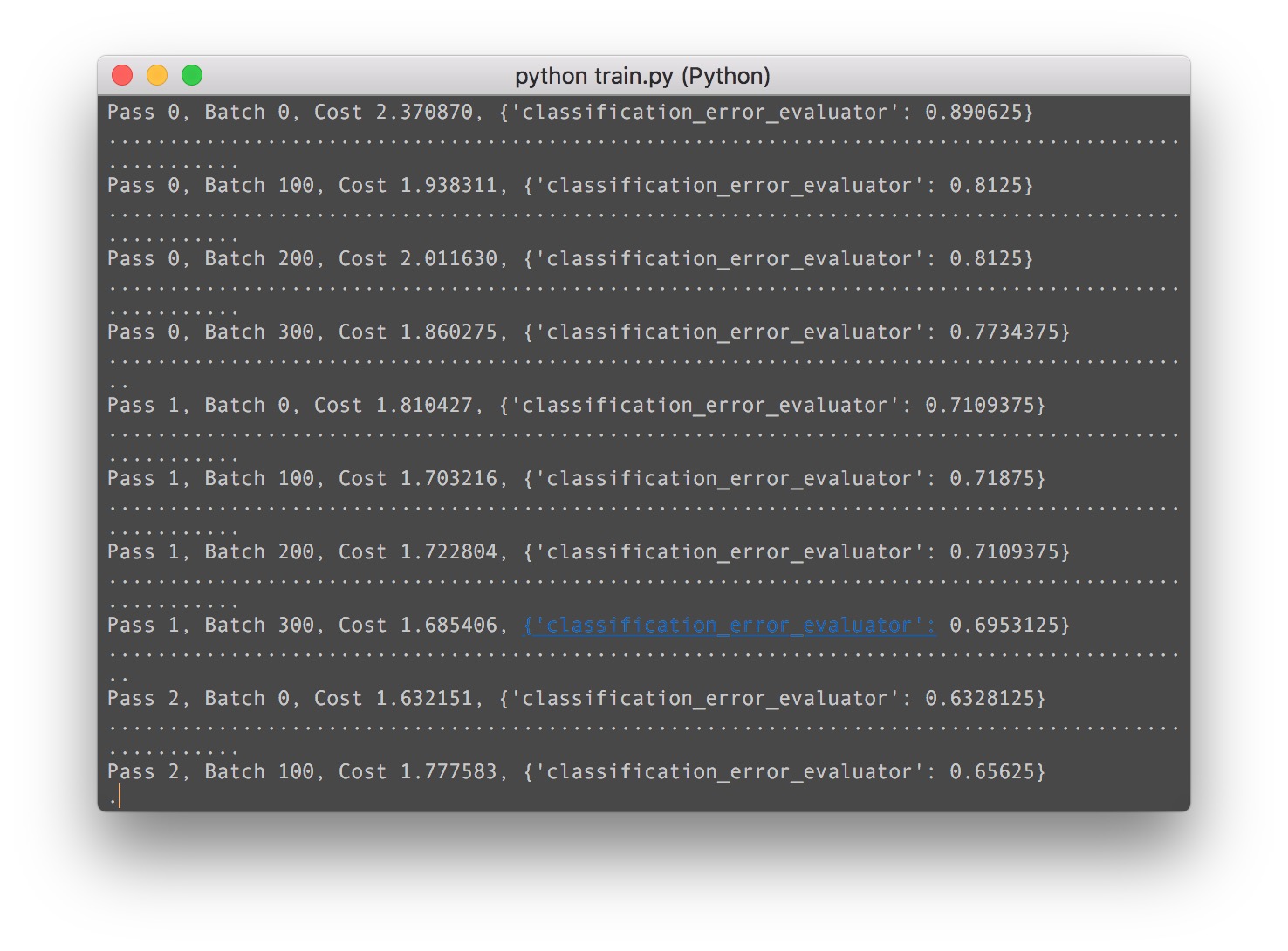
牛逼了我的哥。接下来我们用这个代码来保存网络训练之后的权重:
1 2 3 4 5 6 7 8 9
| try: trainer.train( reader=reader, num_passes=200, event_handler=event_handler, feeding=feeding) except KeyboardInterrupt: with open('params_model.tar', 'w') as f: parameters.to_tar(f)
|
最后,模型train好之后,导入模型进行预测:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| from __future__ import print_function from PIL import Image import numpy as np import os def load_image(file): im = Image.open(file) im = im.resize((32, 32), Image.ANTIALIAS) im = np.array(im).astype(np.float32) # PIL打开图片存储顺序为H(高度),W(宽度),C(通道)。 # PaddlePaddle要求数据顺序为CHW,所以需要转换顺序。 im = im.transpose((2, 0, 1)) # CHW # CIFAR训练图片通道顺序为B(蓝),G(绿),R(红), # 而PIL打开图片默认通道顺序为RGB,因为需要交换通道。 im = im[(2, 1, 0),:,:] # BGR im = im.flatten() im = im / 255.0 return im test_data = [] cur_dir = os.getcwd() test_data.append((load_image(cur_dir + '/image/dog.png'),)) # with open('params_pass_50.tar', 'r') as f: # parameters = paddle.parameters.Parameters.from_tar(f) probs = paddle.infer( output_layer=out, parameters=parameters, input=test_data) lab = np.argsort(-probs) # probs and lab are the results of one batch data print("Label of image/dog.png is: %d" % lab[0][0])
|
OK, 本次列车到此结束,对于paddle如何训练一个图片分类器,应该有了一个清醒的认识,下一步,我们将继续….用paddlepaddle实现一个NLP情感分类器!

